Why GitOps?
GitOps is a set of practices centered around storing your application and infrastructure configuration in Git. The goal being to leverage the capabilities of version-control for your entire systems configuration. If you’re already embracing GitOps practices for your other configuration, then aligning your feature flags with these same practices can complete the experience. No more correlating what changed in Git, with what changed in your feature flag system to understand the entire state of the world. Git is the single source of truth as GitOps intended. So how do we achieve this with Flipt?What You’ll Learn
In this guide you will:- 🏁 Add a feature flag to an existing codebase
- 📝 Define the flag via Flipt’s configuration format
- 🌲 Add, commit, and push the change to a production-serving branch
- 🎯 Adjust our configuration to target an internal group of users in our organization
- 🌓 Progressively enable the flag for proportions of the user base
Setting the Scene
Our guide starts with an imaginary organization with a single web application defined in Go and committed to a GitHub repository. We as the developer, have been tasked to experiment with a new sorting algorithm on an endpoint for our application. Our application handles requests from authenticated users. These users also happen to be grouped into organizations. We will use this information in our targeting rules later on. This endpoint happens to list out a bunch of strings in a JSON array. The sorting algorithm previously used was slow (Bubble Sort), and we want to try something new (Quicksort). While we feel confident in our implementation, we’re going to practice caution and release the change behind a feature flag.The Application
If you want to follow along you can fork our gitops guide
repository.
https://github.com/organization/repository.git.
The target of our change is a http.HandlerFunc definition (in the file pkg/server/words.go) with the name ListWords.
Currently, the function uses a sorting function bubblesort and we’re going to swap this for the quicksort function.
pkg/server/words.go
Calling Flipt
Instead of callingbubblesort directly, we’re going to use the Flipt Go SDK to switch this call based on the feature flag use-quicksort-algorithm.
This flag is going to be a boolean type flag, and so we use the sdk.Evaluation().Boolean() call to evaluate the enabled property of our flag.
We provide this evaluation call with a request containing the flags key, an entity ID and a context map.
getUser(r.Context()).
Our context map is going to contain a single key organization, which is populated by a call to getOrganization(r.Context()).
This will also return an identifier, only this time for the requesting user’s organization.
Flipt’s Declarative Backends
The focus of this guide is to leverage Flipt’s new “declarative backends” to enable a GitOps workflow. The name comes from the fact that the backend for Flipt is modeled around configuration files in a directory structure. These configuration files can coexist in a directory alongside other content (application code or other configuration code). There currently exist three top-level declarative backend types:local(local directory)git(remote Git repository and branch)object(object storage, currently only AWS S3)oci(OCI registry storage)
local and git backend types.
Defining Flag State Locally
In order for our application to work, it now depends on communicating with an instance of Flipt. We’re going to configure our instance using afeatures.yml file in the root of our existing project.
Then we will configure Flipt to serve directly from our local directory.
You don’t have to call your file
features.yml and you can spread your flag
definitions across multiple files. Checkout our docs on locating flag
state to learn more.use-quicksort-algorithm flag.
This flag will be a boolean type flag and be in a disabled (enabled = false) state.
features.yml
Running Flipt Locally
Now the flag is defined in the current directory, we can run Flipt and configure the directory as the source of truth. This is useful for validating behaviour locally, before committing and pushing flag state to a production tracked Git repository. The following command runs Flipt in Docker, with the local directory mounted and Flipt configured appropriately.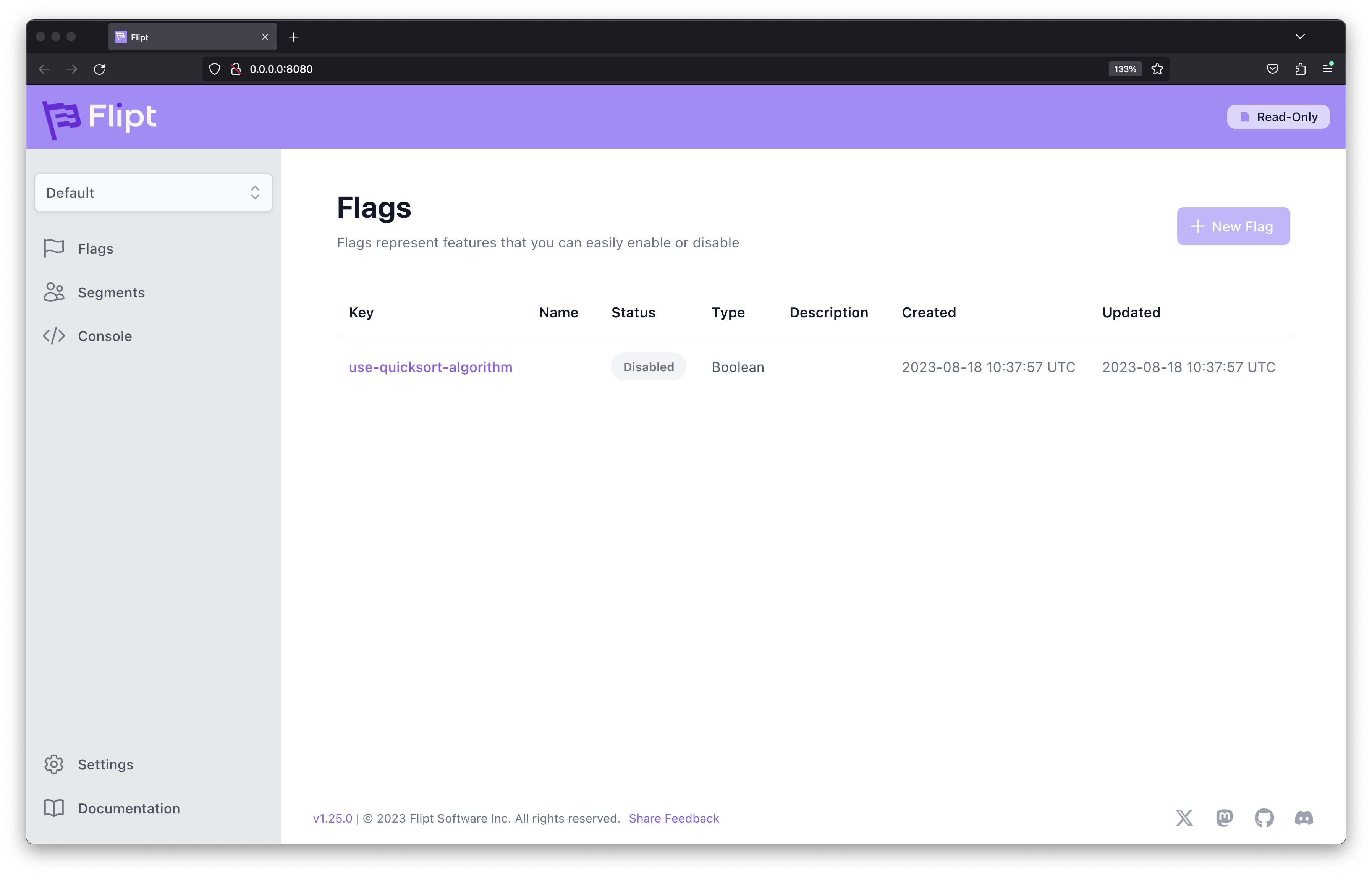
This image demonstrates what can be seen in the Flipt UI with the configuration file we defined being served.Now that Flipt is running locally, our application can also be run and configured to target our local instance of Flipt available at both
http://localhost:8080 and grpc://localhost:9000 (depending on your protocol of choice). The UI is also available on port 8080, however, it’s running in read-only mode since flag state is configured via the configuration file we defined before.
Running Flipt Over Git
Thelocal backend is useful for experimenting and exploring flag state in your development environment.
However, in a production setting, both the git and the object storage types are more appropriate.
Focussing on git, the following command runs Flipt with a remote Git repository hosted on GitHub and tracking the main branch.
main branch.
Changes will eventually propagate into our running instance of Flipt.
Head to Configuration: Storage: Declarative
Backends to learn more about configuring
these backend types for Flipt.
Pushing Our New Flag To Production
For sake of this demonstration, we’re going to assume Flipt has been deployed and configured in this way for our production environment. Our production deployment of our words endpoint will also have been configured to connect to this running instance of Flipt. Given our repository is now being tracked and served by Flipt, we can add, commit, and push both our changes to our endpoint, as well as our newfeatures.yml file to our branch main.
disabled state.
This is where you would use curl to ensure the service is still behaving as expected:
Targeting and Rollouts
Now that our application is deployed with our code change and is referencing our new flag, we can adjust the state via the configuration file and push the changes to Git. We will start by checking out a new branch, as we’re going to propose our change as a pull request and get review from a colleague.Internal Users
We open thefeatures.yml file and update the definition with a new segment and add a rollout rule on our flag which returns enable = true when the request matches our new segment.
The internal-users Segment
features.yml
organization on the context, with a value internal.
Remember we added the key organization earlier when defining the flag in code.
We used a value derived from the request (getOrganization(r.Context())).
This got the organization identifier for the calling user.
Now, when the user happens to be associated with the internal organization, it will match the internal-users segment in Flipt.
A New Segment Rollout Rule
features.yml
enabled property of the flag under certain conditions.
In this instance, we’re using the segment type rule to say when the request matches the internal-users segment, return the value true.
Now our flag is configured to target internal users and enable the Quicksort algorithm for those users instead.
Proposing and Integrating Our Change
Next, we add, commit, and push the change to our branch.main, Flipt will eventually start serving this new configuration change.
We can now request our application as an authenticated user.
Users inside the internal organization should get results sorted with the new Quicksort algorithm.
Whereas, the rest of users should still be served using the old Bubble Sort algorithm.
Proportional Rollout
Once we’re confident our change is working as expected, since we’ve validated the change in production forinternal users, we can start to roll it out to external users.
We could enable the flag for all users at once, but there is always a chance we’ve missed something during manual validation.
Everyone has the best intentions, however. things get missed. So instead we’re going to start slow and gradually enable it for percentages of our user base.
This will give the change time to bake with your audience.
If anything is wrong, we’ve minimized the effected users to a small subset.
Once again we’re going to checkout a branch.
features.yml and add a threshold percentage rule.
A New Threshold Rollout Rule
Here we’re adding a new, different rollout rule type to our existing flag. Note that we’ve left our segment targeting rule intact. This means our flag will remain enabled for internal users. Rollout rules are evaluated on each request in order. The first rule to match will result in the flags enabled property returning the configuredvalue.
If no rules match, then the flags top-level enabled property is used as the final default return value.
features.yml
20, meaning roughly 20% of entity IDs will match and cause the flag to return enabled = true.
Head to Concepts: Bucketing to learn how this mechanism
is actually achieved.
Proposing and Integrating Our Change
Once again, we add, commit, and push the change to our branch.Closing the Loop
This process can be repeated, each time increasing thepercentage property of this newly added threshold rollout rule.
Once we get to the stage of enabling the flag for 100% of users, we can either set the percentage to 100 or we can remove the targeting rules altogether and set the enabled property to true.
features.yml
quicksort function.
pkg/server/words.go
Recap
We’ve successfully rolled a feature out to production using GitOps practices via Flipt’s declarative feature flag configuration files and declarative backends. Along the way, we had the opportunity to use Git to understand the current state of the world. At each commit, we could’ve fully recreated the configuration of our entire application, including the state of Flipt itself.Further Considerations
Now you have all the tools necessary to practice GitOps with your feature flags. However, in production, your mileage may vary with the different backed types. You might want to consider theobject (and AWS S3 type) or the oci backend if your source Git repositories are large (we’re working on a guide for that now).
The declarative storage backends currently mandate that the UI is read-only.
We’ve thoughts on how this could change in the future, but for now, this is a limitation.
You always have your editor, Git and the SCMs (GitHub, Gitlab etc) for state management in the meantime.
Each of these backends work by polling their sources (git, local directory or object store) and the interval can be configured.
Checkout the Configuration: Storage: Declarative for details on adjusting these intervals.